The AI engineering ladder
How the AI agent market really sorts: not by tool category but by operator maturity stage. The four stages every AI team climbs, drawn from 20 interviews and 4,129 pain quotes.
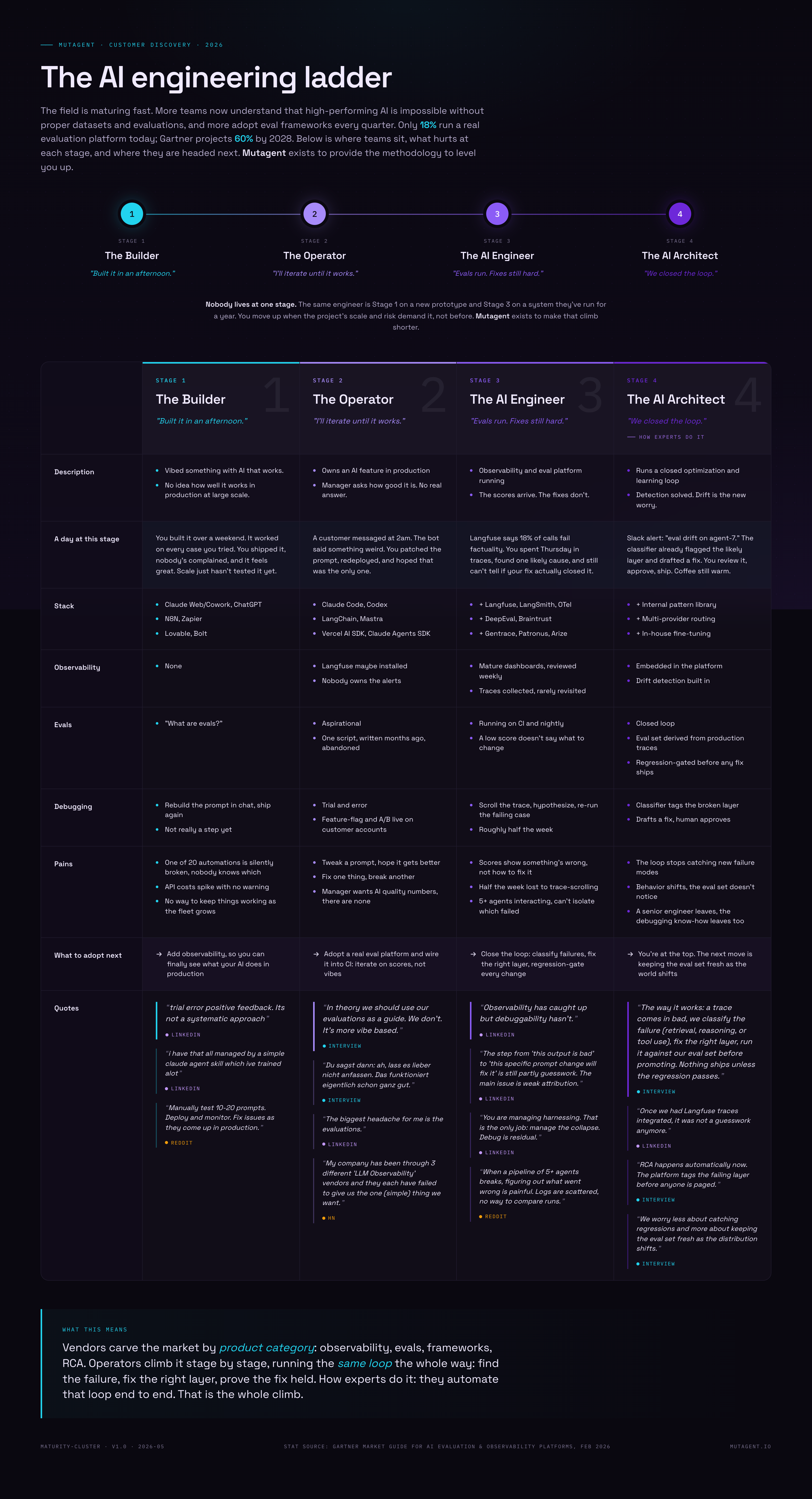
The AI engineering ladder
AI engineering has four stages. The same engineer is on several of them at once, a different rung for every project.
We learned that the slow way. Over three months we ran 20 customer discovery interviews, sat in 89 LinkedIn conversations with AI engineers, and coded 4,129 pain quotes from public engineering forums. We expected to map the market the way the vendors do: a row of boxes labeled observability, evals, agent frameworks, guardrails.
The operators described a ladder instead. 19 of 20 teams running agents in production named the same problem. Their tools were sold to solve a different one.
We sorted what operators said, not what vendors sell
The question was simple: when an AI engineer says their agent “isn’t working,” what do they mean, and what do they do next?
We collected the answer three ways. Twenty structured interviews with teams running agents in production, from a multi-agent procurement company to an AI-native agency to a backend engineer shipping summarization at scale. Eighty-nine conversations in LinkedIn DMs, the kind where someone tells you what their Tuesday actually looked like. And a coded corpus of 4,129 pain quotes from public forums between April 2025 and April 2026, where discussion volume grew fourfold over the year.
This is not a vendor scorecard. We did not rank tools. We listened to operators describe their work, and we sorted what they said.
Vendors carve the market by category. Operators traverse it by stage.
Open any AI tooling market map and you get the same five boxes: observability, evaluation, agent frameworks, guardrails, prompt management. Six logos per box, and a fresh one every week.
No operator we spoke to experiences a box. They experience a stage: a combination of what they have running, what they can do, and what they cannot do yet. There are four.
Nobody lives on a single rung. The same engineer is Stage 1 on a prototype they started yesterday and Stage 3 on the system they have run for a year. The rung is set by the project’s scale and risk, not by the engineer’s skill. You climb when the project demands it, not before.
Stage 1: The Builder shipped something and is quietly hoping
The Builder shipped something with AI that works. Whether it is still working next month is a question they would rather not open.
Their stack is Claude on the web, a Zapier flow, maybe a Lovable app. No observability, no evaluation, because at Stage 1 the word “evals” has not entered the vocabulary. One Builder, asked how he checks his prompts, answered: “What are evals?” He was not being glib. He genuinely had not needed the concept.
The method is honest about itself. “trial error positive feedback. Its not a systematic approach,” one builder told us. A Reddit thread compressed the whole Stage 1 workflow into one line: “Manually test 10-20 prompts. Deploy and monitor. Fix issues as they come up in production.”
This is not negligence. It is the right strategy when the AI thing is small and the blast radius is small. What moves the Builder up the ladder is a decision, not a disaster: add observability, so the next surprise shows up on a dashboard, not a customer’s inbox.
Stage 2: The Operator owns it now, with no way to measure it
The Operator owns an AI feature in production. Their manager asks how good it is. They do not have a real answer.
They have a real codebase and a coding agent driving it. Maybe Langfuse is installed. Evals are almost certainly not running, even though the Operator knows they should be. At Stage 2, evals are aspirational: someone wrote a script months ago, it was abandoned, nothing runs today.
So optimization is feel. The cleanest version came from an engineer at an AI agency: “In theory we should be using our evaluations as a guide for how we change it. We don’t. It’s more vibe based.” A product lead at a multi-agent procurement company described where vibe-based work ends up: “Du sagst dann: ah, lass es lieber nicht anfassen. Das funktioniert eigentlich schon ganz gut.” You end up saying: better not touch it, it works well enough. The agent becomes a thing you are afraid to improve.
The Operator usually tries to buy a way out first. One Hacker News comment is the entire Stage 2 procurement experience: “My company has been through 3 different ‘LLM Observability’ vendors and they each have failed to give us the one (simple) thing we want.”
What moves the Operator up is a real eval platform wired into CI, so iteration finally runs on scores, not vibes.
Stage 3: The AI Engineer has the data and still can’t act on it
The AI Engineer has an observability and evaluation platform running in production. The scores arrive. The fixes do not.
This is the stage with the most tooling and the loudest pain. Traces flowing. Evals on every merge. Dashboards reviewed weekly. And the line our entire dataset kept circling back to: “Observability has caught up but debuggability hasn’t.”
The AI Engineer can see everything and change nothing with confidence. “The step from ‘this output is bad’ to ‘this specific prompt change will fix it’ is still partly guesswork,” one wrote. “The main issue is weak attribution.” So the fix loop becomes regression hell. Change the prompt to close one bad trace, and three others quietly break somewhere else. Whack-a-mole, with a dashboard. When a multi-agent system breaks, attribution gets worse: “When a pipeline of 5+ agents breaks, figuring out what went wrong is painful. Logs are scattered, no way to compare runs.”
The community data agrees. In the 4,129-quote corpus the strongest signal is a three-part loop: cannot identify root cause, stay blind until users complain, own observability tooling that never bridges to a fix. Each of those three cleared the strong-evidence bar on its own.
What moves the AI Engineer up is closing the loop: classify each failure, fix the right layer, gate every change behind a regression eval, until diagnosis is a process instead of a lost week.
03Mutagent Use CaseImprove Runs the diagnose, mutate, evaluate loop and ships verified fixes, each scoped to a root cause and validated on a held-out slice. IN root cause · eval suite OUT verified fix · before/after scorecard


 Explore
Explore
Stage 4: The AI Architect closed the loop, and now worries about drift
The AI Architect runs a closed optimization and learning loop. Detection is solved. Drift is the new worry.
This is the smallest group and the hardest to find. Gartner puts it in numbers: 18% of software engineering teams had an AI evaluation and observability platform in 2025, and 60% will by 2028. Even three years out, the closed-loop operator is not the median.
At Stage 4 the trace-to-fix gap is genuinely closed. “Once we had Langfuse traces integrated, it was not a guesswork anymore,” one operator told us. This is how experts run it: a bad trace gets classified by failure type, the right layer gets the fix, a regression set gates promotion before anything ships.
The residual pain is not detection. It is freshness. The closed loop slowly stops catching new failure modes. User behavior shifts and the eval set does not notice. And when a senior engineer leaves, the debugging knowledge nobody wrote down leaves with them.
The gap is the same at every stage
The four stages look like four different problems. They are one problem at four resolutions.
The problem is the distance between knowing something is wrong and knowing what to change. Observability closed the first half. The industry got very good at collecting traces and lighting dashboards. The second half, the step from a bad trace to a specific fix, is still manual at every stage. Every operator we spoke to was working the same gap, with a different-sized ladder underneath them.
That is why the vendor map misleads. A tool category tells you what someone bought. The stage tells you what they can do. Find an operator’s stage and you know their pain. The logo on their invoice tells you almost nothing.
Find your stage before you buy your next tool
For anyone building AI in 2026: find your stage before you buy your next tool. If you are an Operator, a fourth observability vendor will not move you to Stage 3. A way to turn the traces you already have into a fix will. If you are an AI Engineer, you do not have a tooling gap. You have a methodology gap, and methodology does not ship in a dashboard.
For us, this is what we are building Mutagent around. Not another box on the market map. The loop itself: the diagnose-mutate-validate cycle that takes an operator from a bad trace to a validated fix without the week of guesswork in between.
You already know your stage. You felt it reading this. Next week we show what closing the gap looks like in practice. On Thursday we publish the inner and outer optimization loops, the call of when to simulate a change versus run it and measure. On Friday we run the diagnose-mutate-validate loop live, end to end, on a real prompt, and the Optimizer opens its public beta the same day. Bring the prompt you are most afraid to touch. We will show you what closing the loop on it looks like.